在操作系统篇中介绍了从操作系统的视角中不同编程语言实现并发的共同的一些概念。本文将会介绍常见的并发模型及不同编程语言是如何实现的。
常见的并发模型
## 并发模型
### 多进程(Multiprocessing)
- Fork
### 多线程(Multithreaded)
- 共享内存通信
- Lock
- Java/Go/Clojure/C
- STM
- Clojure
- 消息传递通信
- CSP
- Go
- Actor
- Erlang/OTP
- Scala/Akka
- Vert.x
### 事件驱动(Event Driven)
- Event Loop
with Multiplexing
- Nginx
- Node.js
- Redis
- Twisted(Python)
- Netty(Java)
多进程(Multiprocessing)
多进程模型是利用操作系统的进程模型来实现并发的。典型的是Apache Web Server,每个用户请求接入的时候都会创建一个进程,这样应用就可以同时支持多个用户。
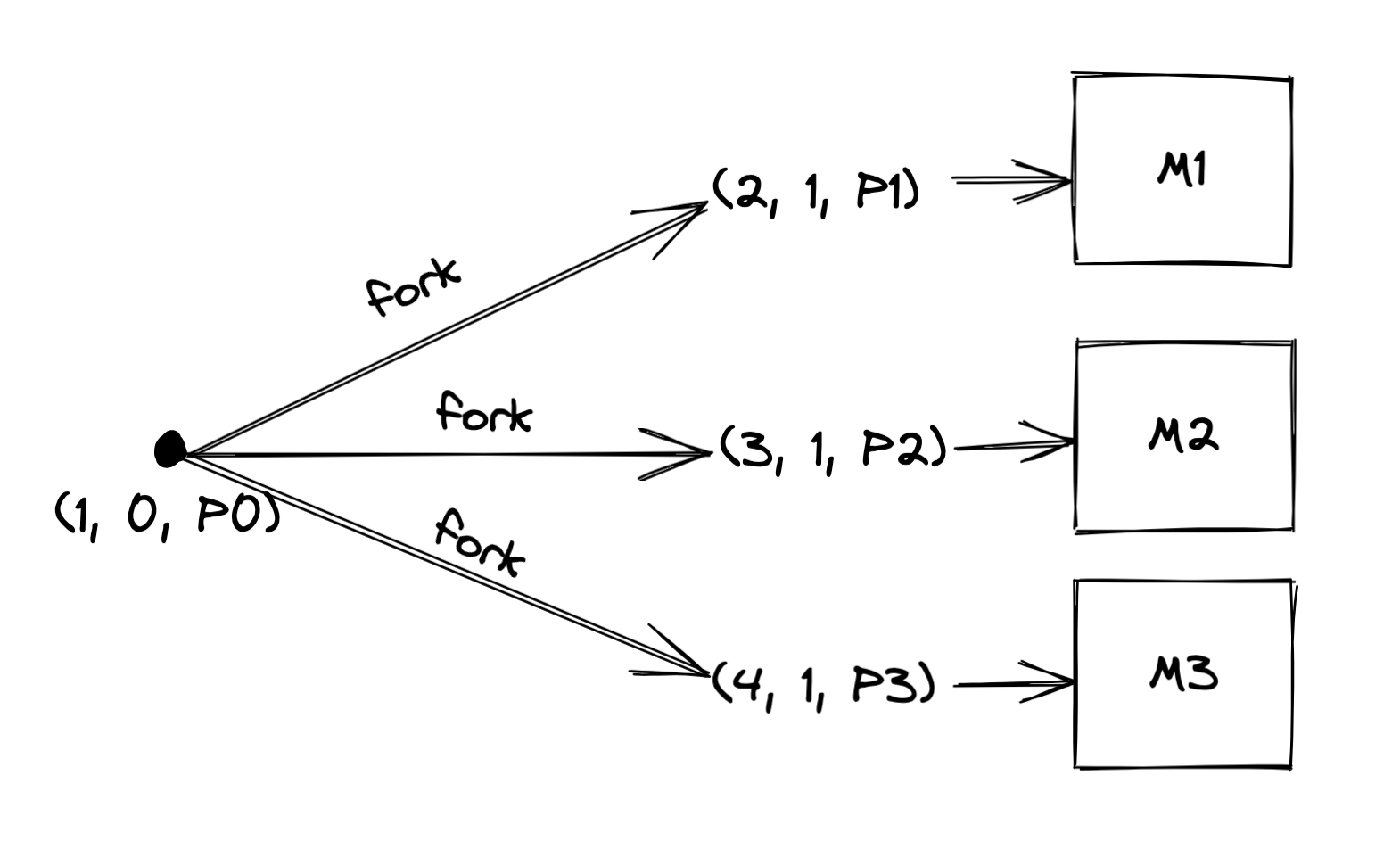
如上图,在Linux系统中PID为1的名为P0的进程通过fork()系统调用创建了3个子进程。在多处理器的系统中,这些子进程可以并行运行在多个处理器上,当然这些进程也可以被同一个处理器通过上下文切换进行CPU分时共享。
在图中M1、M2与M3都代表内存资源,在多进程中如果不同进程想共享内存中的数据必须通过进程间通信的方式来实现。
多进程模型的缺点在于创建进程的开销非常高,如果进程过多会很快消耗光系统资源,并且上下文切换在进程间的开销也很高,在I/O密集型任务的应用中,此并发模型很难满足需求。
多线程(Multithreaded)
在操作系统的视角看,比如Linux中,在进程中创建线程是通过clone()系统调用来实现,这和创建子进程的区别不大。线程与进程的区别在于同一个进程内的线程共享着进程分配的资源,线程不被分配资源,只是操作系统调度执行任务的抽象的最小单元。
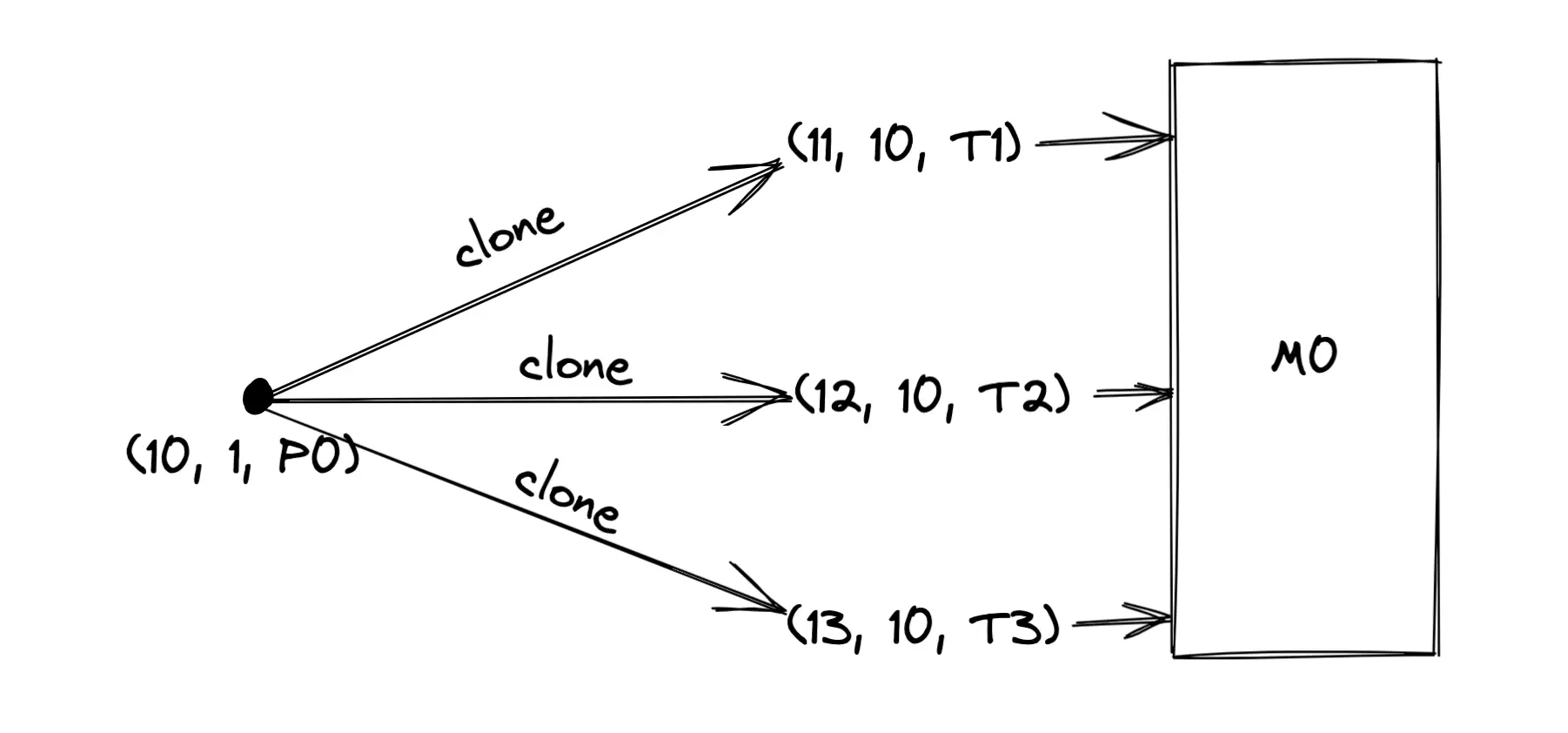
比如下图中,PID为10的进程P0通过clone()系统调用创建了3个线程,这些线程都可以访问进程分配的内存资源M0。
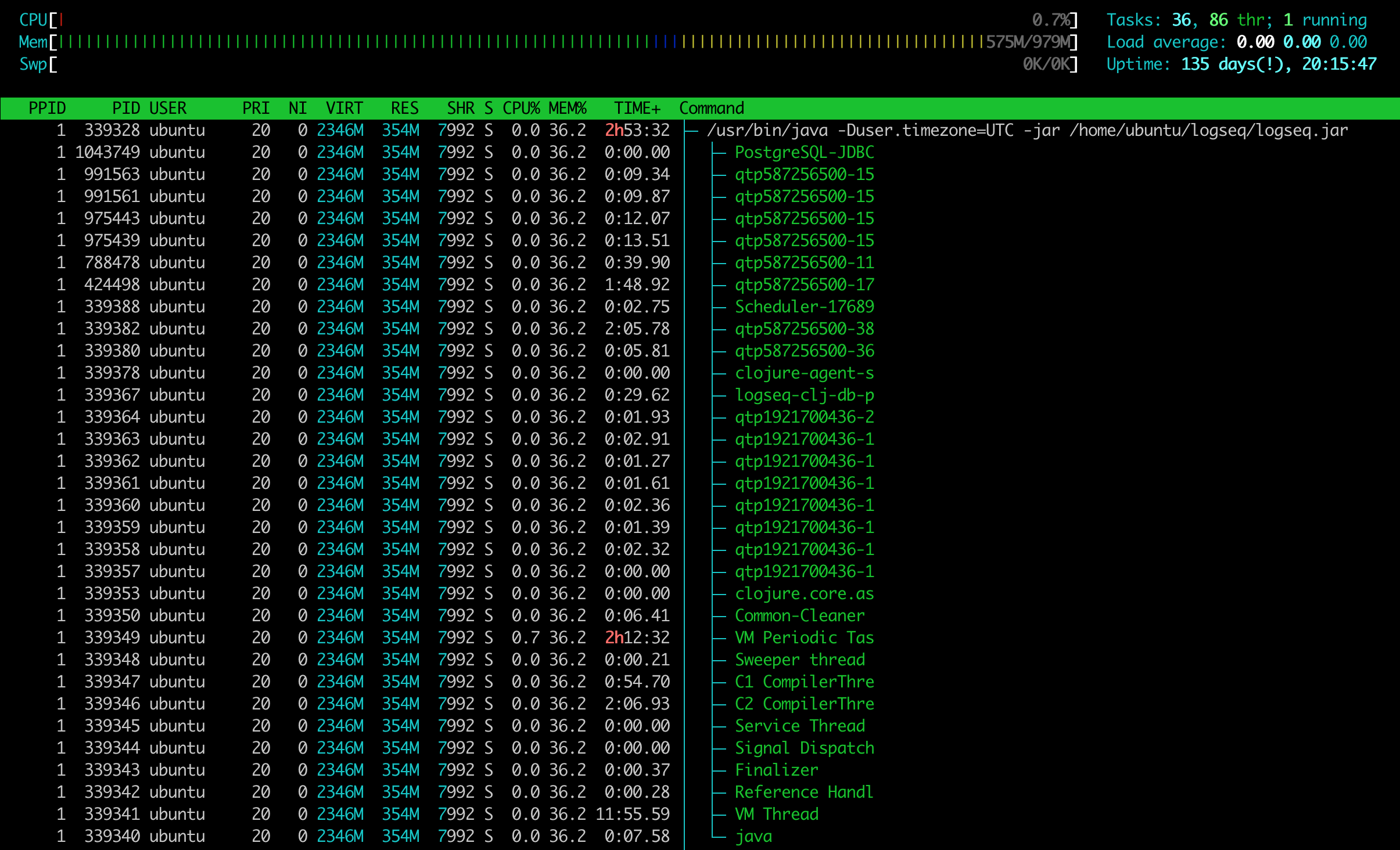
我们也可以通过htop命令在Linux中看到这些进程及线程的运行信息,比如下图中所示PID为339328进程(它是一个基于JVM的Clojure应用)及其创建的线程信息:
也可以通过/proc文件系统获取进程创建的线程的信息:
$ ls /proc/339328/task/
1043773 339340 339342 339344 339346 339348 339350 339357 339359 339361 339363 339367 339380 339388 788478 975443 991563
339328 339341 339343 339345 339347 339349 339353 339358 339360 339362 339364 339378 339382 424498 975439 991561
相比多进程模型来说,因为线程比进程创建的系统开销小,所以多线程模型是很常见的实现并发的方式。但此种模型存在一个必须解决的问题,就是线程间通信的问题。但线程为什么要通信呢?那是因为大部分业务系统问题的解空间在用冯·诺伊曼计算机去实现的时候,都存在并发计算时线程间数据共享的问题。要数据共享有两种方式:
- 共享内存通信(Shared memory communication):不同线程间可以访问同一内存地址空间,并可修改此地址空间的数据。
- 消息传递通信(Message passing communication):不同线程间只能通过收发消息的形式去通信,数据只能被拥有它的线程修改。
共享内存通信(Shared memory communication)
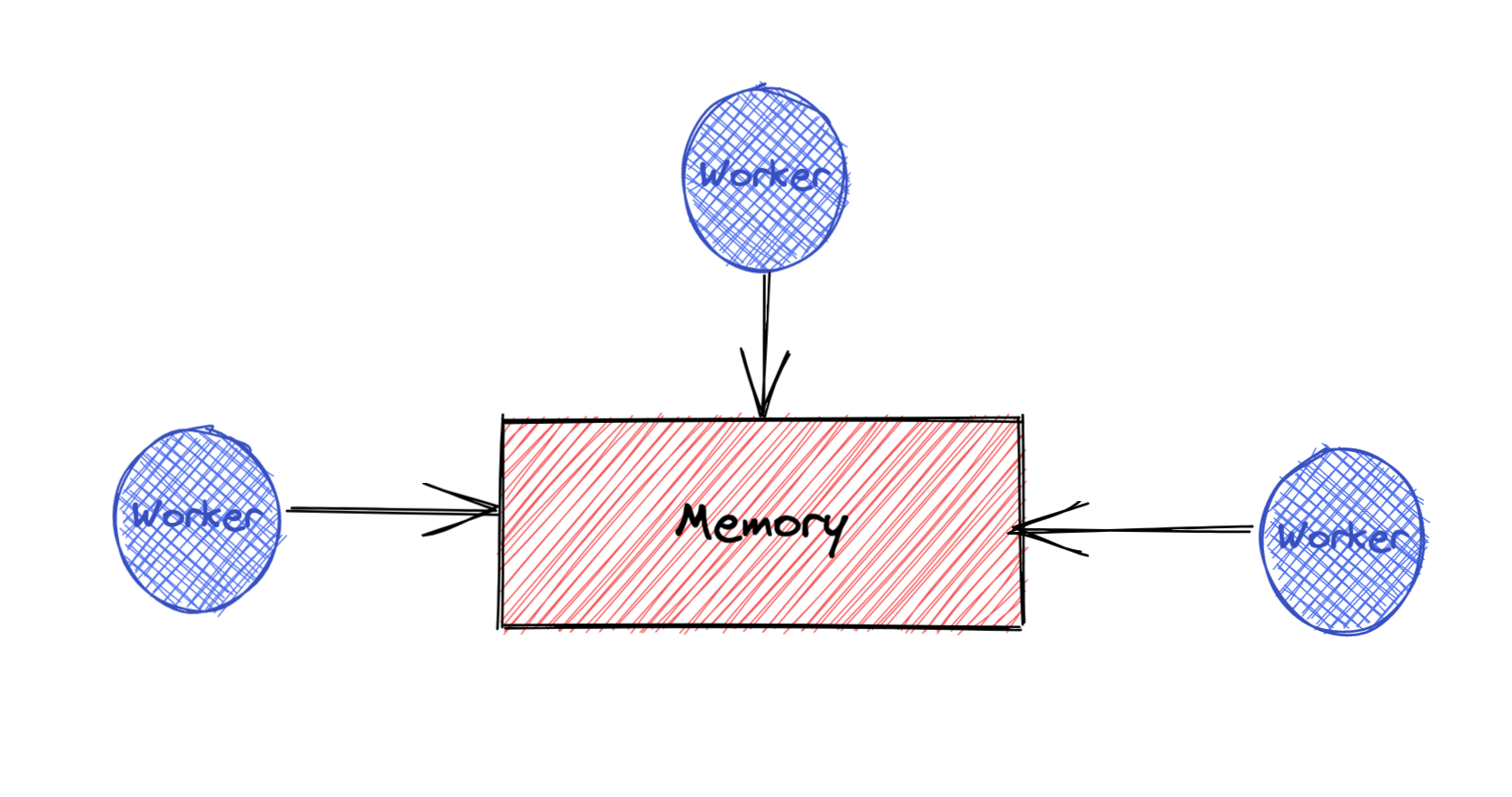
因为线程间共享内存资源,在访问临界区域时会出现数据竞争(发生竞态条件,即代码的行为取决于各操作的时序)的问题,如果不能正确的处理此问题,程序会产生线程不安全的问题,最终导致程序崩溃或无法正常运行。
解决竞态条件的方式是对数据进行同步(Synchronize)访问。要实现同步访问常见的方式有:
- 锁(Lock):通过锁定临界区域来实现同步访问。
- 信号量(Semaphores):可以通过信号量的增减控制对一个或多个线程对临界区域的访问。
- 同步屏障(Barriers):通过设置屏障控制不同线程执行周期实现同步访问。
Lock

锁(Lock),也叫互斥量(Mutex)。线程在操作临界区域资源时,需要先获取锁,然后才能操作,当操作完成后,需要释放锁。此模型利用了对底层硬件运行过程的形式化,这让其即简单又复杂。从锁的种类就可以看出来其复杂性:
- 自旋锁
- 递归锁
- 乐观/悲观锁
- 公平/非公平锁
- 独享/共享锁
- 偏向/轻量级/重量锁
- 分段锁
对锁的使用不当还会产生死锁问题(Deadlock)。在实际开发过程中,能不用锁就不用锁,可以考虑使用一些轻量级的替代方案如原子变量(Atomic),或无锁(lock-free)非阻塞(non-blocking)算法实现的数据结构。
原子变量的更新为何是线程安全的?因为CPU提供了CAS(Compare-and-swap)的指令来更新原子变量,这条指令从硬件上确保了此操作是线程安全的。
此模型的优点:
- 大多编程语言都支持此模型;
- 贴近硬件架构,使用得当性能很高;
- 是其他并发模型的基础;
此模型的缺点:
- 不支持分布式内存模型,只解决了进程内的并发同步;
- 不好调试与测试,想用好不容易;
STM
锁模型是一种悲观的并发同步机制,但实际上冲突发生的概率并不高,所以乐观的并发同步机制性能更好。STM(Software transactional memory)就是这样一种用来代替锁模型的乐观并发同步机制。STM是用软件的方式去实现事务内存(Transactional memory),而事务内存中的事务(Transactional)正是关系型数据库中的概念,一个事务必须满足ACID性质,如下图所示:

在t0时刻,T1、T2与T3线程同时获取要操作的同一数据的快照v0,之后T1线程在自己的事务里于t1时刻提交自己的写入值v1,之后T2线程在自己的事务里提交自己的写入值v2,由于在提交时刻会做冲突检测,此事务发现操作数据的快照已经发生变化,于是回滚自己的提交。之后开启新的事务重新获取最新的快照v1,并于时刻t2成功提交自己的写入值v2。在线程v3中由于是读取操作,并没有数据修改,所以在它的事务中使用的是最早的快照v0。
在STM的事务中尽可能避免副作用,比如在事务中去修改原子变量这种操作,可能会导致事务回滚失败。
STM实现的一种方式是基于MVCC(Multiversion concurrency control)。很多编程语言提供了这种并发模型的实现。
此模型的优点:
- 相比锁模型更简单;
- 大部分情况下更高效;
此模型的缺点:
- 在事务内需要避免产生副作用;
- 不支持分布式内存模型,只解决了进程内的并发同步;
消息传递通信(Message passing communication)
在锁模型中,生产者和消费者之间的通信是通过共享内存而完成的,要实现安全通信,必须给共享内存所属的临界区加锁。那如果生产者和消费者是通过消息传递完成通信的呢?那样我们就可以摆脱锁模型的限制了。
Do not communicate by sharing memory. Instead, share memory by communicating. Communication forces coordination. (Ivo Balbaert)
CSP
通信顺序进程(CSP(Communicating sequential processes))是一种形式语言,用来描述基于消息传递通信的安全并发模型。如下图所示:

这些任务块之间的通信是基于通道(Channel)来完成的,当创建了一个通道之后,不同的任务块就可以通过持有这个通道来通信,通道可以被不同的任务块共享。通道两端任务块的通信可以是同步的,也可以是异步的。
在这里的任务块不是如Java里重量级的线程类,在运行时是非常轻量级的代码块。这些代码块可以被调度到不同的线程中,最终被多个CPU内核并发执行。
此模型的优点:
- 相比锁模型更简单;
- 很容易实现高并发;
此模型的缺点:
- 不支持分布式内存模型,只解决了进程内的并发同步;
Actor
演员模型(Actor)是一种类似面向对象编程思想的安全并发模型。在面向对象的世界里,对象是一种封装了状态及行为的实体,对象间通过消息去通信(通过对象调用其方法)。而在Actor模型中,一切皆Actor,每个Actor中都有自己的状态,其他Actor只能通过通信的方式来获取或修改被通信Actor的状态。Actor通信的方式类似收发邮件,它有自己的收件箱,如下图所示:

在上述图中,我们可以看到相比CSP模型,Actor模型可以跨节点在分布式集群中运行。实际上Actor模型的代表Erlang正是天然分布式容错的编程语言。
此模型的优点:
- 相比锁模型更简单;
- 很容易实现高并发;
- 支持分布式内存模型,能实现跨节点的并发同步;
此模型的缺点:
- 存在信箱满后消息丢失的问题;
Vert.x
Vert.x是一个基于JVM的反应式模型的工具包,在解决并发同步的问题上它采用了类似Actor模型的方式,如下图所示:

在它的架构里最基本的计算单元名为Verticle,这些Verticle之间通过事件总线(Event Bus)进行异步通信,当然也可以像Actor一样跨节点通信。和Actor模型不同的地方在于Vert.x支持多种语言,因为Event Bus解耦了实现Verticle的语言限制。
事件驱动(Event Driven)
在多线程方式实现的并发模型中,我们解决问题的方式是通过创建更多的线程来提高系统的并发处理能力。但线程创建的开销及线程间上下文调度切换的开销并不是很小,所以纵使系统的硬件资源很充足,也存在一定的上限。那么有没有可能只创建一个线程,而且这个线程可以同时处理很多个任务呢?当然是可以的,这正是基于I/O多路复用的事件循环处理并发模型的解法,通过单线程来并发处理I/O密集型的任务。
Less is more.
Event Loop with Multiplexing

此模型巧妙的利用了系统内核提供的I/O多路复用系统调用,将多个socket连接转换成一个事件队列(event queue),只需要单个线程即可循环处理这个事件队列。当然这个线程是有可能被阻塞或长期占用的,针对这种类型的任务处理可以单独使用一个线程池去做,这样就不会阻塞Event Loop的线程了。
此模型的优点:
- 单线程对系统资源的占用很小;
- 很容易实现高并发;
此模型的缺点:
- 不支持分布式内存模型,只解决了进程内的并发同步;
编程语言的实现
许多编程语言标准库或三方库都已支持上述大多数的并发模型,但因为一些历史原因带来的兼容性问题,开发者的使用体验好坏不一。以下仅简单介绍下各种编程语言标准库对并发模型的实现及流行三方库的扩展支持。
Java
Java是一门面向对象的编程语言,标准库对并发的支持是基于共享内存通信的锁模型,因此用Java的标准库来实现高并发是一件非常有挑战的事情,想不踩坑太难。
想深入了解Java的并发模型,可以参考《Java并发编程实战》。
当然基于Java的三方库实现了很多并发模型,如:
- Actor: Akka
- Event Loop with Multiplexing
Go
在Go流行的时期流传着一个故事:一个PHP的普通开发者在一周内学会了Go语言,之后开发出了一个高并发的Web应用,要用Java实现同样的性能,至少需要多年的经验。
暂且不论这个故事是否合理,但它展示了Go语言的两大亮点:
- 语法简单易学;
- 天然支持高并发模型;
Go在语言层面实现了CSP并发模型,因此能让开发者以非常低的成本写出高并发的Web应用。在对CSP并发模型的实现中,Go任务块一般是一个函数,这个函数的调度是由Go语言的调度器来完成,可以被调度在不同的线程中。如果在这个函数中出现了阻塞线程的如网络I/O的操作,调度器会委托给Netpoller去执行,而Netpoller的底层正是对操作系统I/O多路复用技术的封装。
Go高并发的秘诀在于它的G-P-M运行时调度模型,详细的设计可参考这篇文章:Scheduling In Go : Part II - Go Scheduler。
Erlang/Elixir
Erlang是一门天然分布式、高并发、容错的编程语言,它是Actor并发模型的代表编程语言。Elixir是基于Erlang虚拟机(BEAM)的一种不纯粹的、动态类型的函数式语言。它们自然原生支持Actor并发模型,所以在开发高并发的分布式容错应用时,可以考虑使用Elixir,它强大的并发模型及富有表达力的语法可以提供非常好的开发体验。
Erlang的虚拟机在运行时实现了软实时抢占式调度,详细的信息可参考这篇文章:How Erlang does scheduling。
Clojure
Clojure是基于JVM平台的Lisp方言,是不纯粹的、动态类型的函数式语言(这点倒和Elixir类似)。Clojure可以直接调用Java的库,这让其可支持非常多的并发模型,但最有特色的就是它的标准库实现了STM的并发模型,官方提供的异步库core.async也实现了CSP的并发模型。当然还可以通过Nginx-Clojure实现基于I/O多路复用的高并发模型。
Clojure支持非常多的并发原语,想了解可参考这篇文章:Clojure Concurrency Tutorial。
走向高并发
1999年的时候C10K的问题被提出,当时在单机上并发处理上万的连接是一件富有挑战的事情,最终借助操作系统提供的一些支持如进程调度与I/O模型,通过一些高并发的模型如I/O多路复用,我们可以在单机上支持上万甚至更多的并发连接。
二十多年过去了,互联网从Web1走向了Web3,联网的设备从PC走向了IoT,我们已经到了万物互联的时代。C10K的问题已经转变为C10M的问题,如何在单机上支持百万乃至千万的连接呢?
在这篇The Road to 2 Million Websocket Connections in Phoenix中我们可以看到如何用Elixir的Web框架Phoenix在一台40核128GB内存的机器上支撑两百万的Websocket长链接,最终因Linux内核的限制而无法进一步提高并发链接数,并没有达到服务器的极限。
Migratorydata甚至使用Java在一台12核96GB内存的机器上支撑了上千万的Websocket长连接,更多细节见这两篇文章:
- How MigratoryData solved the C10M problem: 10 Million Concurrent Connections on a Single Commodity Server
- Reliable Messaging to Millions of Users with MigratoryData
当单机并发达10K时,内核是解决方案,当单机并发达10M时,内核是瓶颈。比如Linux内核需要32GB内存来维护上千万的Socket连接。所以在单机千万级的解决方案需要在内核之外的应用层去做更多的事情,感兴趣的读者可以看这篇文章:The Secret to 10 Million Concurrent Connections -The Kernel is the Problem, Not the Solution。
总结
在软件开发过程中,安全至关重要。编程的两大安全难题是线程安全与内存安全。这个系列的两篇文章都是在尝试介绍不同编程语言是如何解决线程安全从而更容易的实现高并发。
另外一个想借助这篇文章分享的一个观点是:问题可以被更复杂的方案去解决,当然也可以通过另一种截然不同的思路去更简单的解决。当你觉得一个方案很复杂的时候,试着去找一个完全不同方向的方案,也许会更容易一些。
参考资料
- I/O Models
- Concurrency is not Parallelism (it’s better)
- Callback vs Promises vs Async Await
- Sync vs. Async vs. Concurrent vs. Parallel
- What are Linux Processes, Threads, Light Weight Processes, and Process State
- Latency Numbers Every Programmer Should Know
- Cooperative User-Level Threads (Coroutines)
- Green threads - Wikipedia
- multithreading
- Ask HN: Erlang and network connections?
- Thread (computing) - Wikipedia
- Concurrent Programming for Scalable Web Architectures
- Concurrency Models
- Software Transactional Memory
- Vert.x concurrency model
- The event loop - JavaScript | MDN
- Faster async functions and promises · V8
- 透过 rust 探索系统的本原:并发篇
- 并发模型
- 七周七并发模型
更新日志
2022-05-27:初稿发布。
2022-05-07:开始写作。