# 时间
## 物理时钟
### 时间标准
#### 与地球自转相关
##### 恒星时
##### 太阳时
#### 与天体运动相关
##### 历书时(Ephemeris Time)
##### 相对论力学时
#### 与谐波振荡相关
##### 原子时
###### 国际原子时(TAI)
###### 协调世界时(UTC/Zulu time)
###### GPS时
### 时钟仪器
#### 太阳钟
#### 机械钟
#### 石英钟
#### 原子钟
### 时钟同步
#### PTP
#### NTP
#### GPS
#### 北斗授时
#### TrueTime
### 时间表示
#### ISO 8601
#### RFC 3339
#### Unix Time/Timestamp/Epoch time/Posix time
### 时钟类型
#### 墙上时钟(Wall Clock)
#### 单调时钟(Monotonic Clock)
## 逻辑时钟
### 相关理论
#### 狭义相对论(Special Relativity)
#### 序理论(Order theory)
##### 偏序(Partially ordered set)
##### 全序(Total order)
#### 因果排序(Causal ordering)
### 算法
#### Lamport timestamp
#### Vector clock
#### 混合逻辑时钟
#### 布隆时钟(Bloom clock)
### 应用场景
#### 分布式锁
#### 分布式节点状态同步(Replication)
#### 数据冲突检测
#### 强制因果通信
#### CRDT
#### 实时协作应用(Collaborative)
多出一秒让互联网暂停
2012 年 6 月 30 日,很多互联网在线服务系统和网站突然同时宕机,包括知名的社区 Reddit:
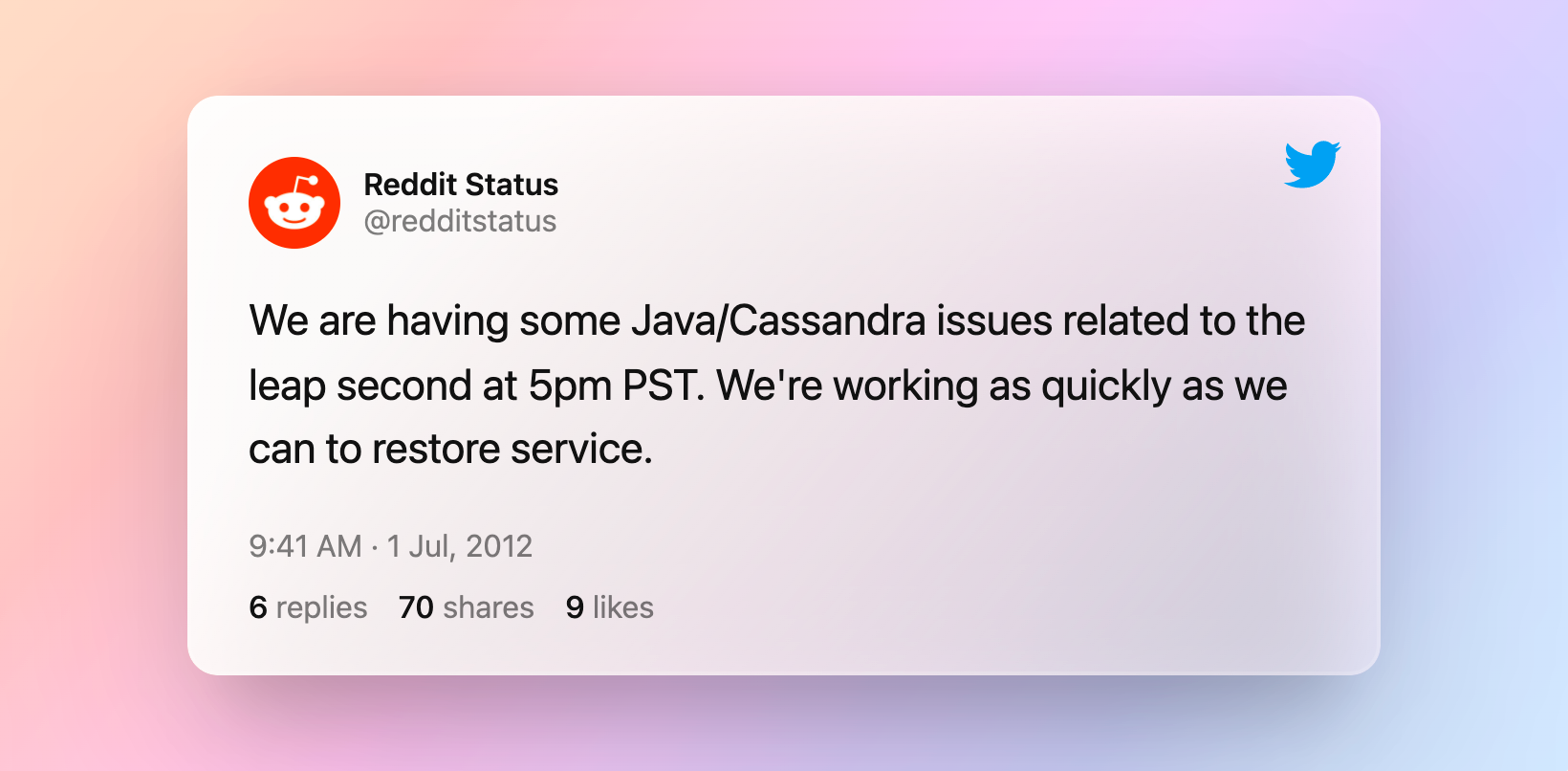
这并不是什么大规模黑客攻击或底层基础库如最近的 Log4j 安全事件引发的,而是一个被人忽略的和时间相关的现象导致的错误。
WIRED 的这篇 The Inside Story of the Extra Second That Crashed the Web 文章详细的报道了这个事件,原因简单来说是:
- 由于地球自转速度并非恒定,导致每隔一段时间协调世界时(UTC)与太阳时(Mean Solar Time)、世界时(UT1)出现微小的偏差。国际地球自转服务(IERS)基于实际地球自转确定何时必须插入闰秒(leap second)来纠正协调世界时与地球自转的偏差,于是他们决定在 2012 年 6 月 30 日最后一秒插入闰秒。
- 由于闰秒的特殊性,很多 IT 应用系统选择直接忽略它,依靠操作系统来处理这多出一秒的影响。问题就出在 Linux Kernel 对闰秒的处理上产生了 Bug。
- Linux Kernel 的一个子系统 Hrtimer 负责唤醒因等待 CPU 时间片而睡眠的进程。但因为闰秒的影响,Hrtimer 在 Linux 内核还未完成任务前提前 1 秒唤醒了睡眠的进程,进而导致了 CPU 过载而无法正常工作。
- 由于 Linux 是很多互联网服务的操作系统,这导致了大量的互联网服务停止服务,整个互联网按下了暂停键!
很难想象因为月球、潮汐等对地球自转的影响,间接导致了整个互联网暂停🤯。但这就是无处不在时间的力量。
当然 Linux 内核最终修复了这个错误,对技术细节感兴趣的可以看这篇 Resolve Leap Second Issues in Red Hat Enterprise Linux。
更有意思的是同样的事情在五年后又发生在了知名 CDN 厂商 Cloudflare 上,这次闰秒事件的起因是 Cloudflare 的 DNS 服务是用 Go 语言开发的,而当时的 Go 并没有单调时钟(后面会介绍到)的 API。闰秒配合 Go 没有单调时钟的缺陷这一组合拳直接打的 Cloudflare 猝不及防。具体分析见这篇文章 How and why the leap second affected Cloudflare DNS。
现实世界中的时间
时间的两个特征
从维基百科对时间的定义中提到:
借着时间,事件发生之先后可以按过去-现在-未来之序列得以确定(时间点/时刻),也可以衡量事件持续的期间以及事件之间和间隔长短(时间段)。
哲学家对于时间有两派不同的观点:一派认为时间是宇宙的基本结构,是一个会依序列方式出现的维度,像艾萨克·牛顿就对时间有这样的观点。包括戈特弗里德·莱布尼茨及伊曼努尔·康德在内的另一派认为时间不是任何一种已经存在的维度,也不是任何会“流动”的实存物,时间只是一种心智的概念,配合空间和数可以让人类对事件进行排序和比较。
这里面无论是定义,还是哲学家的观点,都提到了时间和事件发生序列的关系。
在物理学爱因斯坦的相对论中,时间与空间一起组成四维时空,构成宇宙的基本结构。时间与空间都不是绝对的,观察者在不同的相对速度或不同时空结构的测量点,所测量到时间的流逝速度是不同的。在狭义相对论中,发生在空间中不同位置的两个事件,它们的同时性并不具有绝对的意义,我们没办法肯定地说它们是否为同时发生。
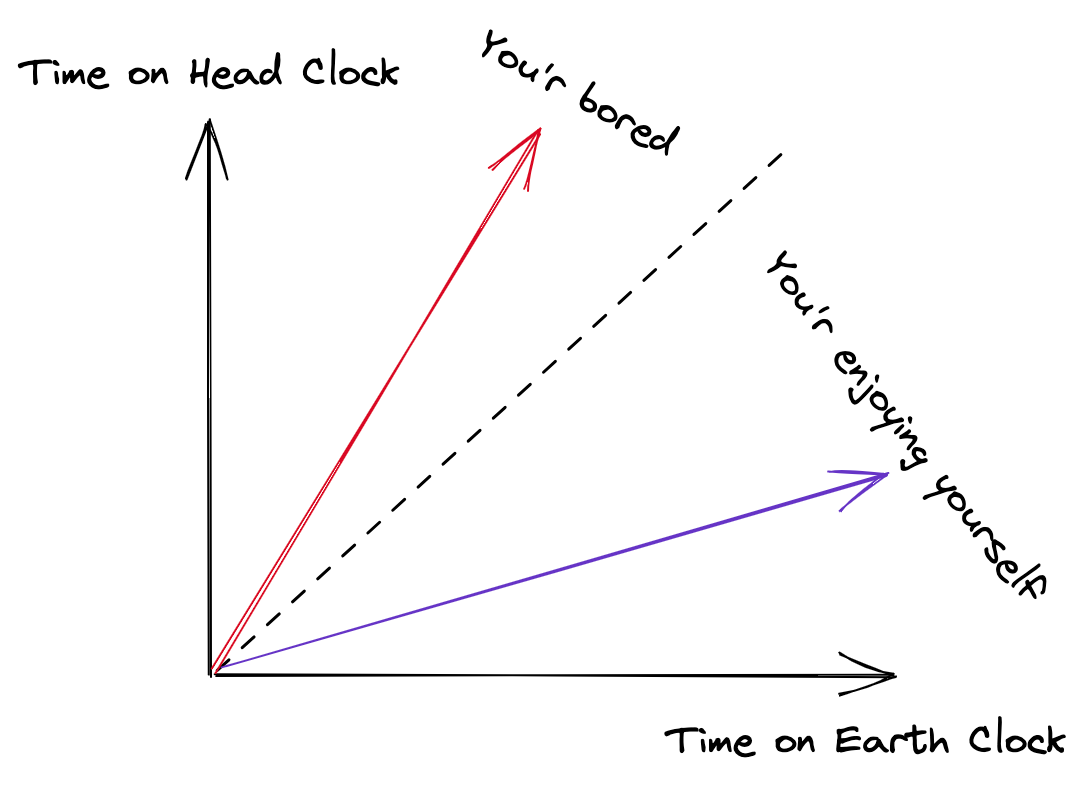
在相对论中,时间的定义复杂了很多。因为参考系的不同,时间中的序列的先后次序也有了一些不同。在同一个参考系中,随着时间的推移,事件出现的先后次序有因果关系。但在不同参考系中,事件出现的先后次序并没有因果关系。也就是说视角不同,事件的相互次序很难被判定。
明白时间的两个特征对之后我们理解分布式系统中的时间问题有很大的帮助:
- 在同一个参考系(视角)中事件发生的先后次序是确定的,可以判定事件的因果关系;
- 在不同参考系(视角)中事件发生的先后次序是不确定的,不一定能判定事件的因果关系。
物理时钟
人类很早就尝试通过一些方法丈量时间了,比如早期的太阳钟(日晷):

时间标准
太阳钟和地球自转现象相关,和地球自转相关的时间标准有恒星时与太阳时,而在太阳时下又分为民用时(平太阳时)和世界时(UT1)。还记得我们刚开始的和闰秒相关的故事吗?我们通过闰秒来纠正 协调世界时(UTC)和太阳时的差异。协调世界时(UTC)是与谐波振荡相关的时间标准下的原子时类别。在原子时里还有国际原子时(TAI)与卫星导航系统(GPS)使用的原子时。
时间标准反应了人们观察时间的视角。虽然原子钟是以原子的能级跃迁为基础建立的时间基准,但它追踪的是太阳时,也就是从地球自转的视角观察时间的流逝。还有一类是与天体运动相关的时间标准,比如历书时与相对论力学时。不过在计算机中用的时间标准现在大多都是原子时。
时钟仪器
有了时间标准,如何通过仪器去实现精确记录时间的功能?这又是一个漫长的历史发展过程,这其中时钟仪器经历了以太阳影子、水流、燃点线香、沙漏、以砝码带动的机械、钟摆、电子、石英甚至原子等方式的发展。各种方式的尝试,只是为了找到能更精确记录时间的方式。目前的原子钟就是人类现在科技能实现的最精确的记录时间的方式。计时方式越来越精确,也反应了社会越来越快的节奏。
时钟同步
有了精确的时间源,如何给网络上的计算机设备同步时间?这方面有以下几种协议:
- PTP(Precision Time Protocol):精确时间协议 (PTP) 是一种用于在整个计算机网络中同步时钟的协议。在局域网中,时钟精度达到亚微秒级,适用于测控系统;
- NTP(Network Time Protocol):网络时间协议 (NTP) 是在互联网上进行时钟同步的一个网络协议,位于OSI模型的应用层。具体可看这篇 计算机的时钟(一):NTP协议 的介绍;
- GPS(Global Positioning System):通过 GPS 来实现高精度的时间同步;
- 北斗授时:和 GPS 一样可提供高精度的时间同步;
- TrueTime:Google 设计的用来给其分布式数据库 Spanner 精准同步时间的算法。相比 NTP 协议,误差小很多。具体见这篇 计算机的时钟(四):TrueTime 的介绍;
计算机或智能设备大多采用 NTP 协议来同步时间。你还可以访问 time.is 这个网站来查看你的设备与高精度原子钟的时间偏差:

时间表示
时钟表示时间的方式很简单,但计算机在内部如何表示时间?有三个常用时间格式的标准:
- ISO 8601:在 Linux 中输入
date --iso-8601=ns会得到 ISO 8601 格式的时间2021-12-25T19:31:12,753290000+08:00; - RFC 3339:在 Linux 中输入
date --rfc-3339=ns会得到 RFC 3339 格式的时间2021-12-25 19:31:10.900897000+08:00; - Unix timestamp:在 Linux 中输入
date +%s获得当前时间的 Unix 时间戳1640432950。它是自 Unix 纪元(Unix Epoch:1970-01-01 00:00:00.000000000+00:00)以来的不包括闰秒的到现在的总秒数。需要注意的是 Unix 时间戳是协调世界时(UTC)标准。
RFC 3339 可以理解为是 ISO 8601 的一个扩展,所以很多时候可以直接用 RFC 3339 替换 ISO 8601。以 RFC 3339 为例:

也可以用 date --rfc-3339=ns -u 获得协调世界时(UTC)标准的时间格式 2021-12-25 11:45:42.740865000+00:00。任何时间都建议使用 RFC 3339 的 UTC 格式或 Unix 时间戳做时间表示,Unix 时间戳在存储和网络传输方面耗费资源更少:

时钟类型
大多时候我们不会意识到计算机在与 NTP 服务器同步时间时的一些影响,但在某些场景比如统计某个程序函数的执行时间时,时间同步会让计算机的本地时间突然向前或者回拨,当程序在做时间差统计的时候,可能会带来错误的值(比如负数),这是墙上时钟(Wall Clock)的弊端。
而单调时钟(Monotonic Clock)则是一种更简单的时间表示方式,它不会被 NTP 服务器影响,但是它也不能保证时间的精确性,因为它只能保证时间的递增或递减,而不能保证时间的绝对准确。
在 Java 中 System.currentTimeMills() API 返回的就是墙上时钟时间,System.nanoTime() API 返回的是单调时钟时间,后者可以用来在日志中统计程序函数执行时间。
分布式系统中的时间
重新认识程序
什么是程序?估计很多人会回答 程序 = 算法 + 数据结构。但这只从静态的角度描述了程序,而程序的价值是在运行的时候。如果从运行时的角度看呢?Leslie Lamport 在这个 Programing Should Be More Than Coding 课程中给出了他的解释:

一个程序可以看作一系列行为的集合,而一个行为又可以看作一系列状态的转换。这个和天然分布式的 Erlang 的世界观有异曲同工之妙:

在 Erlang 的世界观里,程序是由一系列独立的进程组成的,这些进程通过消息传递(Message)来通信共享状态。消息传递的是什么?消息传递的是状态,而状态的转换是由进程来完成的。这个消息传递就是上述中的行为,从这个角度看,程序是由大量的消息传递行为(事件)组成的。
因果一致性
在单节点的程序里,有全局的墙上时钟,大量的消息传递行为并不会出现因果关系的错误。请看如下的例子:
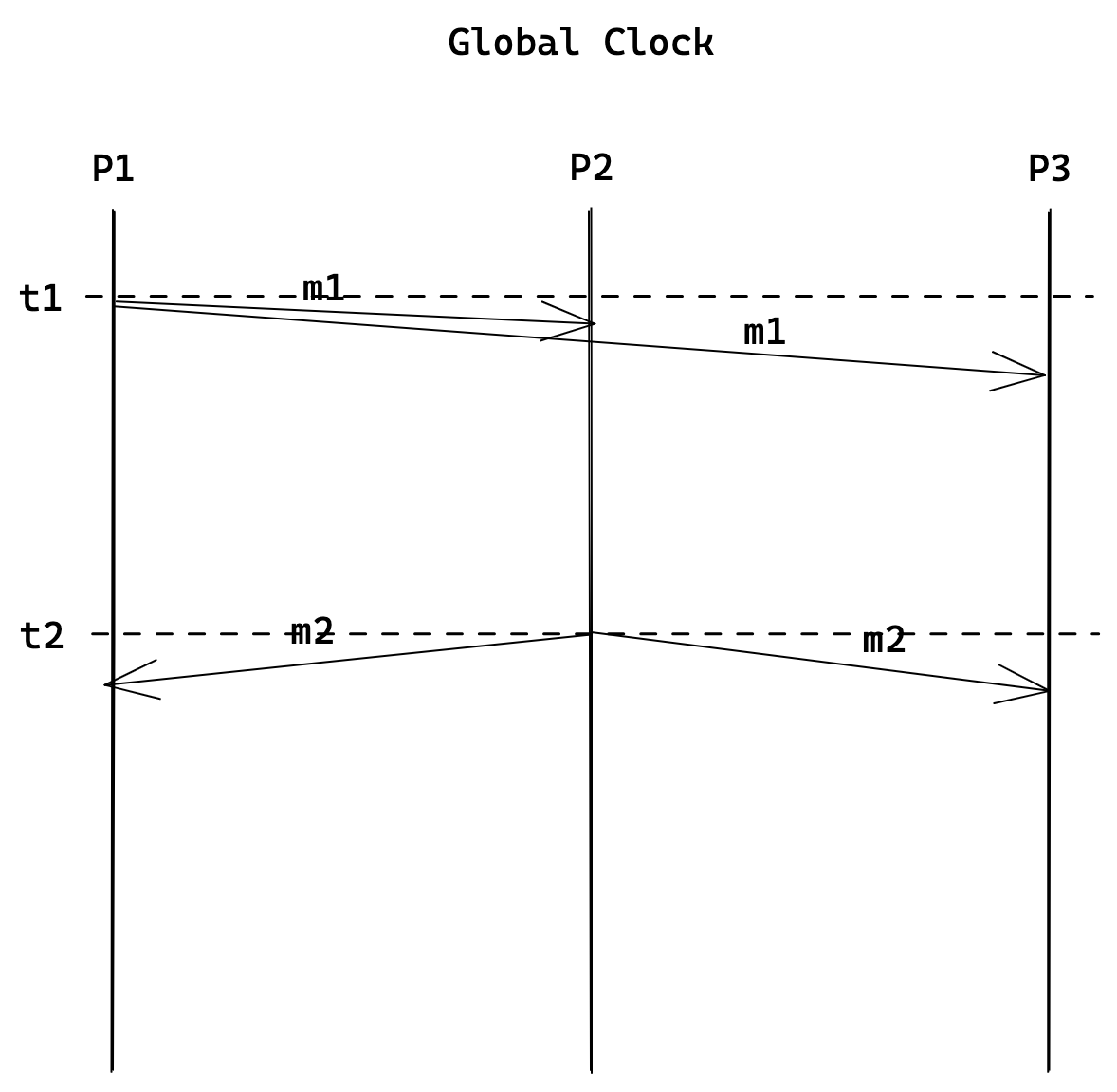
如上图,当进程 P2 收到 P1 发来的消息 m1 后,经过处理之后 P2 将 m2 发送给 P1 和 P3。因为全局时钟的存在,t1 < t2,所以在 P3 进程的视角看,肯定是先收到一个 P1 发来的 m1,然后再收到一个 P2 发来的 m2。实际上,我们程序的逻辑也是 P2 收到 m1 后经过处理才生成 m2,于因果关系上,先有 m1,然后才有 m2。不可能出现 P3 先收到 m2,然后再收到 m1 的情况。
举个实际的例子就是,小王(P1)发了个朋友圈,说“天好美”(m1),小李(P2)看到后评论了一句“好美!”(m2),小赵(P3)看到的肯定是先小王发的,然后小李评论的,不太可能出现先看到小李的评论,然后再看到小王的朋友圈的情况。
但在分布式系统中,因为网络原因和节点同步时钟会产生一定的偏差,可能会出现因果悖论。请看如下的例子:
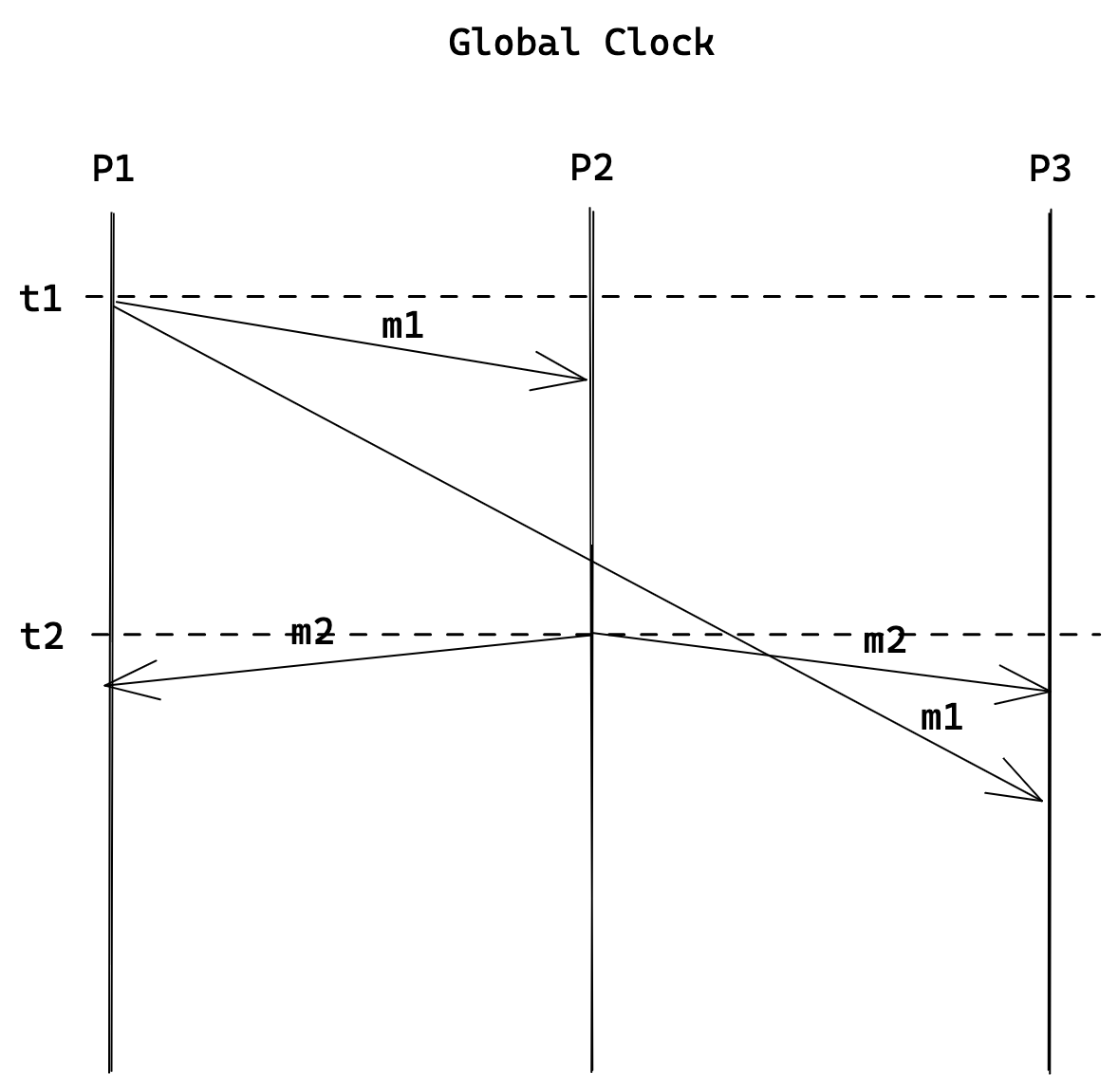
和上面的例子的区别在于,此时的进程分布在不同的节点,甚至可能在物理上相距很远。因为时钟无法做到极高的精确性,此时可能会在不同节点上出现 t2 < t1 的情况。站在 P3 的视角,它很难判断到底是先有 m1 还是先有 m2:
- 虽然先收到 m2,后收到 m1,但完全可能是网络延迟,导致 m1 后于 m2;
- 就算 P1 发送 m1 时携带了自己的本地时间戳 t1,P2 发送 m2 时也携带了自己的本地时间戳 t2。但由于 P1 和 P2 的时间并没有完全同步,导致 P2 的 t2 < P1 的 t1。P3 在收到消息后,根据消息携带的时间戳排序,得到了错误的排序,出现了 m2 先于 m1 的因果悖论。
放到上述朋友圈的例子就是小赵先看到了小李的评论,然后才看到了小王发的朋友圈😵。
逻辑时钟
靠物理时钟肯定是解决不了分布式因果一致性的问题了,因为现有的技术无法解决时钟在不同节点完全同步的问题。
这时候一位大神跳出来了,从狭义相对论中得到了启示写了这篇深刻影响分布式系统领域的论文:Time, Clocks and the Ordering of Events in a Distributed System。这位大神正是之前提到的 Leslie Lamport,他同时也是分布式领域极其复杂的 Paxos 共识算法的作者,也是我们接下来要讲到到的 Lamport timestamp 的作者。
Leslie Lamport 在这个 论文背景介绍 中提到:
… Special relativity teaches us that there is no invariant total ordering of events in space-time; different observers can disagree about which of two events happened first. There is only a partial order in which an event e1 precedes an event e2 iff e1 can causally affect e2. …
这段关于狭义相对论的介绍中提到了两个数学概念:全序 与 偏序。简单理解就是宇宙时空中不存在绝对的全序事件顺序(因为很多事件都没有因果关系,也就是没有次序关系)。但当且仅当(iff)事件 e2 是由 e1 引起时(存在因果关系),e2 后于 e1 发生,它们之间存在偏序关系。
既然在分布式中很难解决时钟同步的问题,那就不去解决这个问题。在分布式中同步时钟是为了解决不同节点发出事件的次序(因果关系),那只需要通过某种手段解决这个事件次序的问题就好了。这正是逻辑时钟解决问题的思路。
理论有点复杂,让我们先看看 Lamport timestamp 到底是怎么解决这个复杂的分布式因果一致性问题的吧。
Lamport timestamp
狭义相对论告诉我们宇宙时空中不存在绝对的全序事件,但我们是否可以在有限的分布式节点中构建一个全局的全序逻辑时钟来描述事件顺序?这正是 Lamport timestamp 的解法。
Happened-before
在进行算法介绍之前先介绍 Leslie Lamport 定义的另外一个重要的概念:Happened-before,它定义了如果事件 ei 导致了事件 ej,那么一定 ei 发生在 ej 之前。它满足如下几个数学规则:
- ei 和 ej 是同一个进程内的事件,ei 发生在 ej 之前,则 ei → ej;
- ei 和 ej 在不同的进程中,ei 是发送进程内的发送事件,ej 是同一消息接收进程内的接收事件,则 ei → ej (发送进程和接受进程可以分布在不同的物理节点上);
- 如果 ei → ej 并且 ej → ek,则 ei → ek (满足传递性)。
- 如果两个事件无法推导出顺序关系的话,我们称两个事件是并行的,记作 ei || ej。
第 4 条规则说明 Happened-before 是一种偏序关系。
看到这里熟悉 Java 的人立即意识到在 Java JMM 中就有了 Happened-before 的概念:在多线程编程中,Happened-before 提供了跨线程的内存可见性保证。在编译器执行编译优化的时候,会对指令做重排序,为了保证程序运行的最终正确,JMM 设定了一些 Happened-before 规则,程序员只要遵循这些规则,JMM 就能保证程序的正确运行。
所以 Happened-before 是一种约束,遵循它我们能获得一定的事件次序最终保证。
算法描述
发送进程端:
# event is known
time = time + 1;
# event happens
send(message, time);
接受进程端:
(message, time_stamp) = receive();
time = max(time_stamp, time) + 1;
这个算法描述起来就是:每个节点都维护一个本地永远递增的逻辑时间戳(初始都为 0),节点发送事件时必须携带此逻辑时间戳。每当节点有事件产生或接收时,节点本地的逻辑时间戳就自增 1。当节点接受到一个事件,如果事件逻辑时间戳比本地逻辑时间戳还小就忽略,否则就接收此事件,并更新节点本地的逻辑时间戳,新的值取节点本地逻辑时间戳和接收事件所携带的逻辑时间戳二者的最大值并自增 1。
一个例子

如上图所示,我们以m@(T,P)的模式全局识别一个事件m,比如m1@(1,P1)代表在 P1 进程上发生了事件 m,在 P1 上本地逻辑时间戳为 1。接下来事件的发生如下描述:
- 在 P1 进程上发生了事件
m1@(1,P1),之后 P1 给 P2 和 P3 发送了此事件; - P2 先接收到了此事件,本地更新逻辑时间戳,这个事件在 P2 中为
m1@(2,P2)。之后 P2 更新了 m1,本地变为m1@(3,P2),并将此事件传播给 P1 和 P3; - 在 P1 中又对 m1 进行了两次更新,在 P1 中 m1 为
m1@(3,P1)。之后 P1 收到了 P2 发来的 m1,因为接受的事件为m1@(3,P2),但本地的 m1 为m1@(3,P1)。两者的逻辑时间戳都一样大,此时是难以区分到底选择哪个版本的 m1,因为无法确定这两个版本 m1 的因果关系; - 在 P3 中先接收到了 P2 发来的
m1@(3,P2),因 P3 之前并无 m1,所以接收此事件并更新为m1@(4,P3)。之后 P3 收到了 P1 发来的m1@(1,P1),因为接收事件的逻辑时间戳小于 P3 本地的逻辑时间戳,所以忽略了此事件。
通过上述描述,我们解决了在 因果一致性 中描述的 P3 无法区分从 P1 和 P2 发来两个版本 m1 的问题。
局限性
如上述第 3 步的描述,Lamport timestamp 算法无法识别并行事件。在 P1 的视角里它无法确定是选择自己本地版本的 m1 还是 P2 发送的 m1,因为其可能是并行事件,毫无关系,也可能是Happened-before的因果关系。
从序论的角度分析,是因为 Lamport timestamp 通过构造一个全序关系来描述实际上是偏序关系的问题集。如果两个事件毫无关系,它们的逻辑时间戳的大小比较毫无意义。
不过在上述例子中,P1 最终选择了通过比较事件的节点大小来确定是否接收事件。在这里我们的冲突解决策略是如果同一事件相同逻辑时间戳,我们选择节点小的值的事件,也就是 P1 > P2 > P3。
Vector clock
Vector clock 解决了 Lamport timestamp 无法识别并行事件的问题。通过构造偏序关系来解决偏序关系的问题集。
Vector clock 在 Lamport timestamp 单值逻辑时间戳的基础上升级为向量(Vector)时间戳。

有了向量的大小比较,Vector clock 将全序改造为了偏序关系,这样就可以识别出事件是否为并行还是Happened-before的因果关系。
如在 P3 收到 P1 发来的事件m1@([1,0,0],P1)时,本地已经有了m1@([1,2,1],P3),因为[1,2,1]比[1,0,0]大,所以忽略了此事件。
但在 P1 收到了 P2 发来的事件m1@([1,2,0],P2)时,本地已经有了m1@([3,0,0],P1),但[1,2,0]与[3,0,0]不可比较,或者说这两个向量平行。此时冲突发生,需要选择一种冲突策略来确定最终接受的 m1 版本。
局限性
Vector clock 虽然解决了 Lamport timestamp 无法识别并行事件的问题,但它也不是一种公平的算法。在冲突出现时,也只能选择提前定义好的冲突策略来确定最终的事件版本。不过在分布式中集群一般会通过共识算法选举一个 leader 节点,通过 leader 节点可以制定一些更合适的冲突解决算法。
另外一个问题在节点数量多的时候,向量会变的很大,网络通信及向量的比较计算都会对系统产生一定的资源损耗。而且也没有考虑节点的动态加入或退出对向量比较的影响。
冲突策略
识别冲突后需要一种冲突策略来解决冲突。这里我们可以选择在 Lamport timestamp 算法中提到的用节点大小比较来确定最终版本,也可以选择 混合逻辑时钟(Hybrid Clock ) 算法。
应用场景
逻辑时钟在分布式系统应用场景非常广泛。比如 构造分布式锁、分布式节点状态同步(Replication)、数据冲突检测、强制因果通信、CRDT 及 实时协作应用(Collaborative) 等。
限于篇幅及能力,这些内容请读者自行查阅研究。
结语
本文通过梳理在现实世界中时间在分布式系统应用会产生的一些问题,介绍了通过引入逻辑时间算法来解决这个问题。可以把逻辑时间理解为分布式系统的一个基石理论,因为当你去研究分布式系统的很多算法,都会发现它的影子。
最后的最后,时间究竟是什么?相信不同人有不同的答案,但当你思考它时,就会发现的影响无处不在。

参考文章 && 进阶阅读
- Time, Clocks, and an Implementation in Erlang
- Distributed Systems 4.1: Logical time
- 逻辑时钟 - 如何刻画分布式中的事件顺序
- Lamport 逻辑时钟(Lamport Timestamp)和 Vector Clock 简单理解
- 计算机的时钟(二):Lamport逻辑时钟
- 从物理时钟到逻辑时钟
- Causal ordering
- Data Laced with History: Causal Trees & Operational CRDTs
- antonkharenko/logical-clocks: Lamport and Vector clocks
- gsharma/vector-clock: Vector clocks & Lamport timestamps
- 从相对论到区块链:论分布式系统中的时间