我们在开发过程中对于文本处理一般会用Regex来搞定,比如识别一个字符串中的邮箱及手机号之类。但是对于复杂的文本格式,我们可能会通过写一个解析工具来解析,但是你可能很难想到用flex/bison来做。想象下这么一个场景,你需要将Nginx的conf文件转换成json格式。
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
}
}
这个格式解析单靠Regex是搞不定的。我们需要更强的Text Processing Tools1。我们知道一门计算机语言和一个Nginx配置文件本质上是由特定词法和语法组成的,了解编译器识别计算机语言的过程有助于我们进一步解决Nginx配置文件的解析。
Compiler Architecture

Compiler Architecture
如上图所示,在我们的问题域中最关心的是Lexical Analysis与Syntax Analysis。
Lexical Analysis
Lexical Analysis将以下的C语言函数:
void do_awesome_stuff(int a, string b) {
/* Code here */
}
Token化为:
TYPE: void
IDENTIFIER: do_awesome_stuff
OPEN_BRACKET: (
TYPE: int
IDENTIFIER: a,
COMMA: ,
TYPE: string
IDENTIFIER: b
CLOSE_BRACKET: )
OPEN_BRACE: {
COMMENT: /* Code here */*
CLOSE_BRACE: }
Syntax Analysis
Syntax Analysis将Token序列解析为Abstract Syntax Tree2:
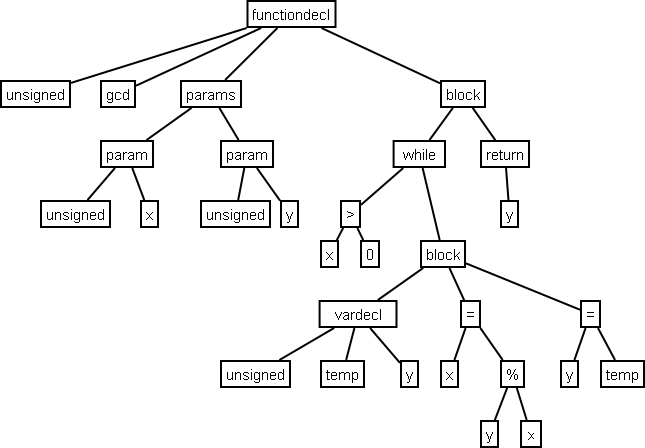
有了AST(抽象语法树)后,可以进一步生成IR(中间语言),也可以在语义分析中做语法正确性检查(如各种语法lint工具)。

BNF/Flex/Bison
如上图所示,第1、2、3步中出现了BNF、Flex、Bison。
BNF(Backus normal form)
Backus–Naur form or Backus normal form (BNF) is a notation technique for context-free grammars, often used to describe the syntax of languages used in computing, such as computer programming languages, document formats, instruction sets and communication protocols. They are applied wherever exact descriptions of languages are needed: for instance, in official language specifications, in manuals, and in textbooks on programming language theory.3
简单来说,BNF是一种用于表示上下文无关(CFG)文法的形式语言(形式语言一般有两个方面:语法和语义,由字母表上的某些有限长字符串的集合)。
CFG(context-free grammars)
在计算机科学中,若一个形式文法 G = (V, Σ, P, S) 的产生式规则都取如下的形式:A -> α,则谓之。其中 A∈V ,α∈(V∪Σ)* 。上下文无关文法取名为“上下文无关”的原因就是因为字符 A 总可以被字符串 α 自由替换,而无需考虑字符 A 出现的上下文。一个形式语言是上下文无关的,如果它是由上下文无关文法生成的。上下文无关文法重要的原因在于它们拥有足够强的表达力来表示大多数程序设计语言的语法;实际上,几乎所有程序设计语言都是通过上下文无关文法来定义的。BNF(巴克斯-诺尔范式)经常用来表达上下文无关文法。4
Flex
Flex在Lexical Analysis阶段用来生成词法分析器。
Bison
Bison用于自动生成语法分析器(Parser)程序,实际上可用于所有常见的操作系统。Bison把LALR形式的上下文无关文法描述转换为可做语法分析的C或C++程序。
LALR/LL/LR
在计算机科学中,LALR分析器是一种规范LR分析方法的简化形式。它可以对上下无关文法进行语法分析。LALR即“Look-Ahead LR”。其中,Look-Ahead为“向前看”,L代表对输入进行从左到右的检查,R代表反向构造出最右推导序列。 LALR分析器可以根据一种程序设计语言的正式语法的产生式而对一段文本程序输入进行语法分析,从而在语法层面上判断输入程序是否合法。 实际应用中的LALR分析器并不是由人手工写成的,而是由类似于yacc和GNU Bison之类的LALR语法分析器生成工具构成。5
LL分析器是一种处理某些上下文无关文法的自顶向下分析器。因为它从左(Left)到右处理输入,再对句型执行最左推导出语法树(Left derivation,相对于LR分析器)。能以此方法分析的文法称为LL文法。6
Automata Theory
我们知道,自动化理论(automata theory)里,有FSA(Finite State Automata)和PDA(PushDown Automata),前者可以用regular expression表述,而后者可以处理CFG(Context Free Grammar)。而CFG便是flex/bison要处理的对象!7

Automata Theory
能被DFA和NFA识别的语言是正则语言。能被PDA识别的语言为CFG语言。几乎所有程序设计语言都是通过CFG来定义的。BNF经常用来表达CFG。
所以我们知道靠正则是解决不了Nginx配置文件这种CFG语言的。这种情况需要我们写BNF文法来解决。
Compiler-compiler
一个编译器编译程序(compiler-compiler)或者编译器产生程序(compiler generator)是一个帮助用户根据某种语言或机器的规则来产生语法分析器,解释器或者编译器的工具。当前最早也是最常见的编译器编译程序是语法分析器产生程序(parser generator)这个形式,其输入是一个编程语言的形式文法 (一般是用BNF表示),然后产生出一些语法分析器的代码,作为这个语言编译器的一部分。
理想的编译器编译程序,只要给予一个编程语言的完整描述以及目标的指令集架构,然后就能自动从中产生出合适的编译器。实际上, 最先进的技术还没有到达这么复杂的地步,而大多数现有的编译器产生程序都不能处理语义学或者目标架构的信息部分。8
不同语言的Parser生成器
| 语言 | Parser |
|---|---|
| c | bison |
| clojure | instaparse |
| javascript | jison |
| javascript | peg.js |
| 各种语言 | antlr4 |
| golang | participle |
| erlang | yecc |
其他的详见 Comparison_of_parser_generators 。
使用JS写一个Parser
了解完上面这么多枯燥的理论,是时候该实战了,让我们使用Parser解决一个真正的问题。在《我的时间管理工具》这篇文章中提到我开发了todo_parser_lib,这个库便是用JavaScript的jison库开发的解析todo文件为json的AST格式的功能。
jison到底有多强,可以从这里感受下: ProjectsUsingJison。
todo文件是一种类似yaml/python缩进风格的纯文本格式的文件,如下:
test1:
☐ test list1 @started(19-12-11 21:16)
> test list1 comm
✔ test list2 @critical @started(19-12-11 21:16) @done(19-12-11 21:17) @lasted(1m2s)
✘ cancel @cancelled(19-12-11 21:28)
test2:
☐ test list21 @started(19-12-11 21:16)
✔ test list22 @critical @started(19-12-11 21:16) @done(19-12-11 21:17) @lasted(1m2s)
✘ test list23 cancel @cancelled(19-12-11 21:28)
test3:
☐ test list31 @started(19-12-11 21:16)
✔ test list32 @critical @started(19-12-16 09:24) @done(19-12-16 09:24) @lasted(41s)
我们最终要生成如下的JSON Scheme:
[
{
"name": "test1:",
"todo": [
{
"name": "☐ test list1 @started(19-12-11 21:16)",
"todo": []
},
{
"name": "test2:",
"todo": [
{
"name": "☐ test list21 @started(19-12-11 21:16)",
"todo": []
}
]
}
]
},
{
"name": "test3:",
"todo": [
{
"name": "☐ test list31 @started(19-12-11 21:16)",
"todo": []
}
]
}
]
step1/词法分析
Javascript的jison自带了词法分析功能,不过也可以使用第三方的词法分析库,由于yaml/python缩进风格的文法,本身不是CFG,需要我们做一定的处理才能正常的Token化9。在这里我们使用lexer来解析缩进风格的文法。
const Lexer = require('lex');
const row = 1;
let col = 1;
const indent = [0];
const lexer = module.exports = new Lexer(function(char) {
throw new Error('Unexpected character at row ' + row + ', col ' + col + ': ' + char);
});
global.flag = 0; // 0 - doing, 1 - critical
module.exports.changeFlag = function changeFlag(flag) {
global.flag = flag;
};
lexer.addRule(/^[\t ]*/gm, function(lexeme) {
const indentation = lexeme.length;
col += indentation;
if (indentation > indent[0]) {
indent.unshift(indentation);
return 'INDENT';
}
const tokens = [];
while (indentation < indent[0]) {
tokens.push('DEDENT');
indent.shift();
}
if (tokens.length) return tokens;
});
lexer.addRule(/\n+/gm, function(lexeme) {
// col = 1;
// row += lexeme.length;
// return "NEWLINE";
});
lexer.addRule(/.*/gm, function(lexeme) {
col += lexeme.length;
const projectRe = /^.*:$/g;
if (lexeme.length == 0) {
// return "EMPTY"
} else if (lexeme.trim().startsWith('> ')) {
// return "COMMENT"
} else if (lexeme.trim().includes('@done') || lexeme.trim().includes('@cancelled')) {
// return "DONE"
} else if (projectRe.test(lexeme.trim())) {
this.yytext = lexeme;
return 'NAME';
} else {
// doing todo item
if (global.flag == 0 && lexeme.trim().includes('@started')) {
this.yytext = lexeme;
return 'NAME';
}
// critical item but is not doing
if (global.flag == 1 && lexeme.trim().includes('@critical') && !lexeme.trim().includes('started')) {
this.yytext = lexeme;
return 'NAME';
}
}
});
lexer.addRule(/$/gm, function() {
col++;
return 'EOF';
});
Token化的核心是使用特殊的Token替代被Token化文件中的符合正则表达式的字符串,我们这里只关注缩进INDENT/DEDENT和Todo待办事项的NAME,还有文件结束符EOF,所以你可以猜到最终被lexer输出的是个Token List:
NAME: test1:
INDENT
NAME: ☐ test list1 @started(19-12-11 21:16)
NAME: ✘ cancel @cancelled(19-12-11 21:28)
NAME: test2:
INDENT
NAME: ☐ test list21 @started(19-12-11 21:16)
NAME: ✘ test list23 cancel @cancelled(19-12-11 21:28)
DEDENT
DEDENT
NAME: test3:
INDENT
NAME: ☐ test list31 @started(19-12-11 21:16)
DEDENT
EOF
step2/语法分析
有了上述Token List做输入给jison做BNF语法分析,最终解析出json AST。先看BNF语法:
{
'bnf': {
'todo-plus': [
['todo-list EOF', 'return $1;'],
['EOF', 'return null'],
],
'todo-list': [
['todo', '$$ = $1 == null ? null : [$1];'],
['todo-list todo',
'if ($1 == null) { $$ = $2; } ' +
'else { if ($2 == null) { $$ == $1; } ' +
'else { $$ = [].concat($1).concat($2); } };'],
],
'todo': [
['item', '$$ = {name: $1, todo: []};'],
['item INDENT todo-list DEDENT', '$$ = $3 == null ? $3 : {name: $1, todo: $3};'],
['item INDENT DEDENT', '$$ = null;'],
['INDENT DEDENT', '$$ = null'],
],
'item': [
['NAME', '$$ = yytext;'],
],
},
}
BNF就是递归的分解要解析的文件字符串,直到遇到不可分割的Token,比如文件一开始肯定会拆解为 ‘todo-list EOF’ ,然后 todo-list 可以进一步分割直到 NAME 和 INDENT/DEDENT ,jison是兼容bison语法的,所以如果一脸懵比可以先看下bison语法帮助文档。
step3/Render
经过语法分析,我们得到了json字符串,在这里我们可以使用mustache.js将json渲染为HTML,我们只需要定义好Template,然后调用mustache render即可。
const Mustache = require('mustache');
const fs = require('fs');
module.exports = function render(doingJson, criticalJson) {
const todoTemplate = fs.readFileSync(__dirname + '/template/todo_template.mustache');
const outputDoingHtml = Mustache.render(todoTemplate.toString(), doingJson, {
recurse: todoTemplate.toString(),
});
const outputCriticalHtml = Mustache.render(todoTemplate.toString(), criticalJson, {
recurse: todoTemplate.toString(),
});
const indexTemplate = fs.readFileSync(__dirname + '/template/index_template.mustache');
const outputIndexHtml = Mustache.to_html(indexTemplate.toString(), {doing: {}, critical: {}}, {
doing: outputDoingHtml,
critical: outputCriticalHtml,
});
return outputIndexHtml;
};
<ul class='todos' style='margin: 10px 0;'>
{{#todo}}
<li class='todo' style='list-style-type: none;'> {{ name }} </li>
{{> recurse }}
{{/todo}}
</ul>
需要在这里注意的时,由于我们的JSON Scheme是嵌套的todo list,所以模版的渲染也需要嵌套10。
step4/工程化
核心代码完成后,我们需要重构,应用一些工程实践,比如单元测试11、命令行工具12、CI自动发布工具到NPM仓库13。
.
├── README.md
├── bin
│ └── todo-cli.js
├── lib
│ ├── ast.js
│ ├── lexer.js
│ ├── parser.js
│ ├── render.js
│ └── template
│ ├── index_template.mustache
│ └── todo_template.mustache
├── package-lock.json
├── package.json
└── test
├── test_data
│ ├── critical.json
│ ├── doing.json
│ ├── test.doing.json
│ ├── test.lex
│ ├── test.todo
│ ├── test1.critical.json
│ ├── test1.lex
│ └── test1.todo
└── test_parser.js
这块不在赘述,感兴趣的可以参考源代码。
Nginx配置文件Parser
让我们回到开始的问题,现在你可以使用BNF去大胆的写一个解析Nginx配置文件的Parser吧。
进一步阅读
创作一门属于自己的Toy Language/Compiler,可以看看这篇文章 Writing Your Own Toy Compiler Using Flex, Bison and LLVM 。
当然也可以看看王垠的 《对 Parser 的误解》 。
想看大型编程语言的语法分析,可以看看Elixir基于Erlang平台是怎么把自己编译成Erlang的:elixir_parser.yrl
References
-
https://zh.wikipedia.org/wiki/%E4%B8%8A%E4%B8%8B%E6%96%87%E6%97%A0%E5%85%B3%E6%96%87%E6%B3%95 ↩︎
-
https://zh.wikipedia.org/wiki/LALR%E8%AF%AD%E6%B3%95%E5%88%86%E6%9E%90%E5%99%A8 ↩︎
-
https://zh.wikipedia.org/wiki/LL%E5%89%96%E6%9E%90%E5%99%A8 ↩︎
-
https://zh.wikipedia.org/wiki/%E7%B7%A8%E8%AD%AF%E5%99%A8%E7%B7%A8%E8%AD%AF%E7%A8%8B%E5%BC%8F ↩︎
-
Looking for examples of Jison grammars that use indentation for block-structure ↩︎